Comparing permissions in two Google Cloud IAM roles
Sometimes you have to compare two Google Cloud IAM roles, and if they have lots of permissions assigned, it can be difficult (or tedious) to find the differences.
We can do it super quick and obvious thanks to the semantic diff used by our friend dyff.
We'll need:
- The
gcloudCLI tool (configured and logged in, of course) -
dyff (you can do it with
diffbut it's uglier)
Example:
SOURCE_ROLE='roles/dataproc.admin' DESTINATION_ROLE='roles/dataproc.editor' dyff between \ <(gcloud iam roles describe ${SOURCE_ROLE} --format=yaml) \ <(gcloud iam roles describe ${DESTINATION_ROLE} --format=yaml)
That will give us this output (but in pretty highlighted colors) in our terminal:
_ __ __ _| |_ _ / _|/ _| between /dev/fd/13 / _' | | | | |_| |_ and /dev/fd/14 | (_| | |_| | _| _| \__,_|\__, |_| |_| returned four differences |___/ description ± value change - Full control of Dataproc resources. + Full control of Dataproc resources. Allows viewing all networks. includedPermissions - ten list entries removed: - dataproc.autoscalingPolicies.getIamPolicy - dataproc.autoscalingPolicies.setIamPolicy - dataproc.clusters.getIamPolicy - dataproc.clusters.setIamPolicy - dataproc.jobs.getIamPolicy - dataproc.jobs.setIamPolicy - dataproc.operations.getIamPolicy - dataproc.operations.setIamPolicy - dataproc.workflowTemplates.getIamPolicy - dataproc.workflowTemplates.setIamPolicy name ± value change - roles/dataproc.admin + roles/dataproc.editor title ± value change - Dataproc Administrator + Dataproc Editor
We could use different options like -b to remove the fancy dyff header, or -o to change the format, for example to GitHub diff, and get syntax highlighting in some places:
dyff between -o github \ <(gcloud iam roles describe ${SOURCE_ROLE} --format=yaml) \ <(gcloud iam roles describe ${DESTINATION_ROLE} --format=yaml)
Output:
SOURCE_ROLE='roles/dataproc.admin' DESTINATION_ROLE='roles/dataproc.editor' @@ description @@ ! ± value change - Full control of Dataproc resources. + Full control of Dataproc resources. Allows viewing all networks. @@ includedPermissions @@ ! - ten list entries removed: - - dataproc.autoscalingPolicies.getIamPolicy - - dataproc.autoscalingPolicies.setIamPolicy - - dataproc.clusters.getIamPolicy - - dataproc.clusters.setIamPolicy - - dataproc.jobs.getIamPolicy - - dataproc.jobs.setIamPolicy - - dataproc.operations.getIamPolicy - - dataproc.operations.setIamPolicy - - dataproc.workflowTemplates.getIamPolicy - - dataproc.workflowTemplates.setIamPolicy @@ name @@ ! ± value change - roles/dataproc.admin + roles/dataproc.editor @@ title @@ ! ± value change - Dataproc Administrator + Dataproc Editor
Check the options for more fun:
dyff between --help
Android private DNS in Hisense (and other) phones with adb
I got a new Hisense A5 phone (pretty interesting, it has an eInk screen), but it has a lot of extra apps that seem to track and phone home, contacting to qq, taobao or baidu domains.
I disabled a bunch of them, but I still saw some connections, so I decided to kill two birds with one stone, and set fixed DNS servers to NextDNS and filter all tracking and unwanted domains.
Since Android 9 you can set a global "Private DNS" (DNS-over-TLS) to force DNS requests to go there, but I've found Hisense removed that option from their ROM (that seems to be called Vision). I don't know if I should be paranoid and think about China government intervention, or it's just the company trying to force you into their tracking and ads, but I wanted to change that option.
But seems that, although that option is not visible, it's still in the underlying Android system, so you can set it up with adb, even without root.
To do that, first get your phone ready to use adb:
Enable developer mode (Normally you would click several times in "Kernel Version" in your "About phone" section in settings)
Enable USB debug in your phone (In a newly activated "Developer options" menu around your settings)
Connect to your computer through a usb cable
Install adb, i.e. with the Debian package of the same name ;)
Run adb devices to verify you can connect to your device, and check your phone for confirmation dialogs
Now, to set the dns, for example, with Cloudflare's DNS over TLS, run this two commands:
adb shell settings put global private_dns_mode hostname adb shell settings put global private_dns_specifier cloudflare-dns.com
To disable:
In my case, I use NextDNS with a custom configuration, and instead of cloudflare-dns.com I use something like xxxxx.dns.nextdns.io.
Locating packages installed with apt in your bash history
So, I'm backing up my computer for reinstall, and I need a list of what packages I've installed so I can install them again.
I could do it dumping dpkg --get-selections, but I don't want to mess with packages status (installed, uninstalled, pending), and just reinstall exactly the pacakges I installed manually.
So, I need:
Listing all packages I've installed with apt or apt-get on my history
Cutting all the junk and leaving only the name of the packages
Important: Finding if those packages are still installed. Maybe I uninstalled them later!
WARNING: This is a quick and dirty recipe, take a look and test the individual commands before using it!
So this is the recipe I used:
for i in `history| \ grep -E "apt install|apt-get install"| \ grep -v grep| \ tr -s " "| \ cut -d " " -f 5-| \ tr " " "\n"| \ sort| \ uniq` do if dpkg -s ${i} > /dev/null 2>&1 then echo ${i} fi done
You might need to modify the -f 5- to -f 6- if you use sudo to install.
You can pipe that into a file and then reinstall like this:
And add that output to an apt install command.
Cheers!
MySQL / MariaDB: Creating new UTF database
Duplicating/cloning an arduino chip using an "Arduino as ISP" and avrdude
So today I had to write several ATtiny85 with a small silly program I wrote years ago to control LED lighting via PWN, but the source was nowhere to be found. I could rewrite it in an afternoon, but my arduino is kind of rusty so I decided to clone an already written ATtiny85 I had around using my Arduino as ISP bought from CT3 I used for projects that didn't need a full arduino board.
Requirements:
An Arduino as ISP board (not necessarily the one I use)
avrdude installed
Some of the actions you'll run might need root permission if you've not configured serial access for your user, or if you have a newer kernel that controls access to dmesg.
First, I connect my Arduino as ISP and check the port it's been assigned:
~# dmesg|tail -n 10 [ 179.219531] usb 2-3.4: reset high-speed USB device number 6 using xhci_hcd [ 4137.875481] usb 9-4: new full-speed USB device number 2 using ohci-pci [ 4138.064654] usb 9-4: New USB device found, idVendor=2a03, idProduct=0043 [ 4138.064661] usb 9-4: New USB device strings: Mfr=1, Product=2, SerialNumber=220 [ 4138.064665] usb 9-4: Product: Arduino Uno [ 4138.064669] usb 9-4: Manufacturer: Arduino Srl [ 4138.064673] usb 9-4: SerialNumber: 85439303333351E02292 [ 4138.102738] cdc_acm 9-4:1.0: ttyACM0: USB ACM device [ 4138.103861] usbcore: registered new interface driver cdc_acm [ 4138.103865] cdc_acm: USB Abstract Control Model driver for USB modems and ISDN adapters
So, ttyACM0, fine!
Then, we put the chip we wanna read on our ISP and read it with avrdude:
~# avrdude -p t85 -P /dev/ttyACM0 -c avrisp -b 19200 -U flash:r:flash.bin:r avrdude: AVR device initialized and ready to accept instructions Reading | ################################################## | 100% 0.02s avrdude: Device signature = 0x1e930b (probably t85) avrdude: reading flash memory: Reading | ################################################## | 100% 5.89s avrdude: writing output file "flash.bin" avrdude: safemode: Fuses OK (E:FF, H:DF, L:62) avrdude done. Thank you.
Sounds about right! We've read the chip and written its contents to flash.bin. Let's swap the chip for the new empty one and write it:
~# avrdude -p t85 -P /dev/ttyACM0 -c avrisp -b 19200 -U flash:w:flash.bin
avrdude: AVR device initialized and ready to accept instructions
Reading | ################################################## | 100% 0.02s
avrdude: Device signature = 0x1e930b (probably t85)
avrdude: NOTE: "flash" memory has been specified, an erase cycle will be performed
To disable this feature, specify the -D option.
avrdude: erasing chip
avrdude: reading input file "flash.bin"
avrdude: input file flash.bin auto detected as raw binary
avrdude: writing flash (1280 bytes):
Writing | ################################################## | 100% 1.83s
avrdude: 1280 bytes of flash written
avrdude: verifying flash memory against flash.bin:
avrdude: load data flash data from input file flash.bin:
avrdude: input file flash.bin auto detected as raw binary
avrdude: input file flash.bin contains 1280 bytes
avrdude: reading on-chip flash data:
Reading | ################################################## | 100% 0.93s
avrdude: verifying ...
avrdude: 1280 bytes of flash verified
avrdude: safemode: Fuses OK (E:FF, H:DF, L:62)
avrdude done. Thank you.
Great! You're good to go! :D
Switching to Nikola
So here we are, testing Nikola on nginx. Will it blend?
Flash no ha muerto [ójala]
No, Flash no ha muerto. Sólo ha cambiado de nombre.
Ya he visto unas cuantas veces publicado hoy que Flash ha muerto, especialmente en ‘redes de blogs’, esos espacios de escritura a destajo y falta de información contrastada. Ya me gustaría que se acabara con Flash, siendo uno de los problemas de seguridad más comunes en los equipos de escritorio. Mis ordenadores nuevo ya no tienen Flash instalado. Too bad.
Sí, es cierto que dicen que van a apoyar la pproducción en formato HTML5, pero ni siquiera se han terminado de leer la breve nota de prensa que claramente dice “… while continuing to support the creation of Flash content…” “…Flash continues to be used in key categories like web gaming and premium video, where new standards have yet to fully mature…” “…Adobe is committed to working with industry partners,[…], to help ensure the ongoing compatibility and security of Flash content”.
Algunos se han molestado un poquito más en hacerlo mejor.
En fin. Al menos está un poquito más cerca de su defunción. Espero.
Waldorf nw1 specs leaked on web
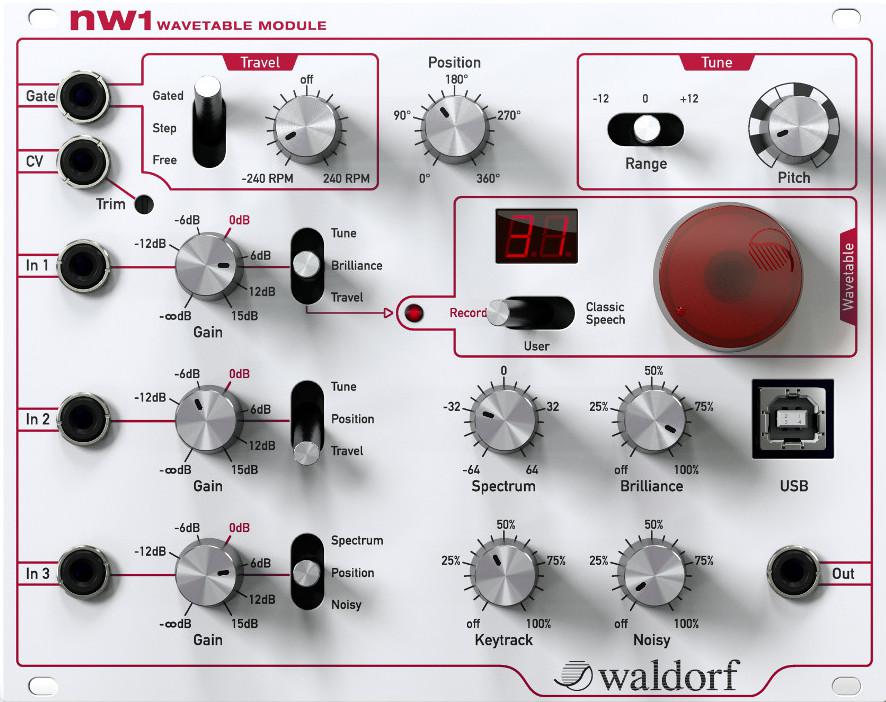
Today we’ve seen a short video about some of the new releases expected for Waldorf, probably for NAMM 2015. Everybody seemed curious and surprised about the new eurorack module nw1 on video, so I’ve been tinkering around Waldorf web page until I’ve found, hidden, the link with the specs:
Specifications:
21st century advanced wavetable engine
Cyclic wavetable scanning with modulatable position and travel speed
Control of spectral envelope independent of pitch
Adjustable periodicity up to noisy reproduction
Classic Waldorf wavetables included
Integrated speech synthesizer for wavetables
User-recordable wavetables
LibreOffice Impress missing sidebar icons on Linux Mint
I’ve noticed after several Mint updates my sidebar icons on Impress were missing, that is, blank. The fix is super easy, you just need to install the package libreoffice-style-tango:
sudo apt-get install libreoffice-style-tango
And that’s all!
You can check, just to be sure, on the menu Tools/options/View, which style is selected.
Go!
Upgrading Proxmox without a subscription
Now, to update Proxmox to the latest versions you need a paid subscription. I don’t mind, it’s a way of supporting their business and they still allow you to download their latest version on an ISO to download.
The subscription is fairly cheap for a production site and their support, AFAIK, is fast.
I have paid subscriptions for my production servers, but I have several testing and development ones I don’t need it, but I would like to update, every once in a while, to newer versions without reinstalling. So the answer is easy: update with the Proxmox ISO.
Backup first!
– Download the latest Proxmox ISO – Mount it on the system as a loop fs:
mount proxmox-ve_3.3.iso /mnt -oloop
– Edit your /etc/apt/sources.list and add this line:
deb file:///mnt squeeze pve
– Update your apt:
apt-get update
– Do dist-upgrade:
apt-get dist-upgrade
– Comment the line you added on /etc/apt/sources.list, reboot, and you’re good to go!